New version!A new version of this website is available at architectural-patterns.net. Event sourcing
 In most cases you are just interested in the current state of your data. There are applications, however, where previous states are just as important, and you need to be able to navigate from one state to another, by code alone. Event sourcing is used when the events that lead to the current state of the data are just as important as the current state itself is. Examples
Where does it come from?
When should you use it?
How does it work?Every action performed by the system is modelled as an event and written to an event store (event log). This store only changes by this adding of events. Events are not removed or modified after they're added. Event takes the form of a diff (difference) (no: set account balance to 110 euro; yes: increase account balance with 10 euro). Since a log of events itself does not make a state, and users need state to interact with a system, the system needs to build a current state from the event log. In the simplest case, a single state is updated each time a new event is added. In a more elaborate case, the system has many views on the same event log, and these are updated asynchronously (as is the case in CQRS). The system may have the ability to tag some event. If so, the system provides lists of tags and the user may be able to revert the system to the state labeled with this tag. 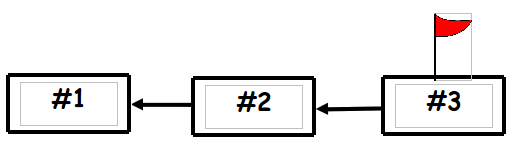 This picture shows the events in the event source. The red flag is the tag that points to the current event. The state of the system reflects all the events up to this point. 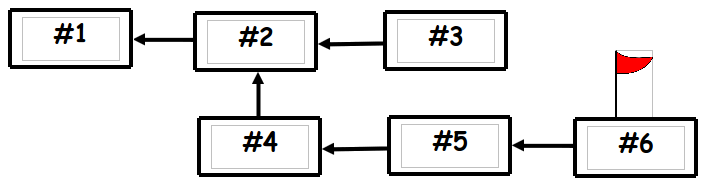 In the second picture a branch has been created starting with event #2. The client that uses the system is working on this branch and has created some events #4, #5, and #6 that exist parallel to the main branch. The state of this client reflects all events up to event #5. At some later state these branches may need to be merged into one again. Problems
Common implementation techniques
Links |
